はじめに
「Perplexityで検索すると競合サイトが引用されているのに、自分のサイトは出てこない」
「Perplexityに引用されるにはどんな対策をすればいいかわからない」
「llms.txtを設置すればPerplexityに表示されると聞いたが、具体的な方法がわからない」
2025年以降、AI検索エンジンとして急成長しているPerplexity。月間アクティブユーザーは数千万人規模に達しており、特に情報収集・リサーチ用途での利用が急増しています。
Perplexityはユーザーの質問に対してWeb上の複数のページを引用しながらAIが回答を生成する仕組みのため、引用元として選ばれるかどうかがサイトへのトラフィックに直結します。
この記事では、WordPressサイトがPerplexityに引用・表示されるための具体的な対策を、仕組みの解説から実装手順まで解説します。
目次
- PerplexityがWebサイトを引用する仕組み
- Perplexityのクローラー「PerplexityBot」とは
- 引用されるサイトの共通点
- Perplexity対策の3ステップ
- llms.txtの設置方法(WordPressでの具体的な手順)
- 引用されやすいコンテンツの書き方
- 引用状況の確認方法
- まとめ
- よくある質問(FAQ)
1. PerplexityがWebサイトを引用する仕組み
Perplexityはユーザーが質問を入力すると、リアルタイムでWebをクロールして関連ページを収集し、その内容をもとにAIが回答文を生成します。回答の下部には引用元のページが「ソース」としてカード形式で表示され、ユーザーはそこから元のページにアクセスできます。
この「引用元として表示される」ことがPerplexityからのトラフィック獲得の基本的な仕組みです。
Google検索との違い
| 項目 | Google検索 | Perplexity |
|---|---|---|
| 結果の形式 | URLリストの表示 | AI生成の回答文+引用元カード |
| クリックの動機 | 自分で記事を読みたい | 引用元の詳細を確認したい |
| 評価軸 | リンク・キーワード・E-E-A-T | 回答としての精度・構造・信頼性 |
| 対策の方向性 | 検索順位の最適化 | AIに引用されやすいコンテンツ構造 |
Google検索対策とPerplexity対策は完全には一致しませんが、「信頼性の高い情報を明確な構造で提供する」という方向性は共通しています。
2. Perplexityのクローラー「PerplexityBot」とは
Perplexityは「PerplexityBot」という独自のクローラーを持っており、定期的にWebサイトをクロールしてコンテンツを収集・インデックスしています。
PerplexityBotのUser-Agent
PerplexityBot/1.0; (+https://perplexity.ai/perplexitybot)サーバーのアクセスログでこのUser-Agentを確認できれば、PerplexityBotがすでにサイトを訪問していることが確認できます。
robots.txtでのクロール制御
PerplexityBotを拒否していないか確認してください。意図せずクロールをブロックしている場合、Perplexityに一切引用されない状態になります。
クロールを許可する設定(robots.txtの例):
User-agent: PerplexityBot
Allow: /注意: WordPressのSEOプラグインのrobots.txt設定でAIクローラーを一括ブロックしているケースがあります。Yoast SEOやRank Mathのrobots.txt設定を確認し、PerplexityBotが許可されているかチェックしてください。
3. 引用されるサイトの共通点
Perplexityに引用されやすいページには、いくつかの共通した特徴があります。
質問に対して冒頭で明確に答えている
Perplexityはユーザーの「質問」に対する「回答」を探します。記事の冒頭で質問への答えを端的に述べ、後半で詳細を補足する結論ファースト構造のページが引用されやすい傾向があります。
長い前置きの後にやっと答えが出てくる記事は、AIが回答部分を抽出しにくいため引用候補から外れるリスクがあります。
ソースカードのタイトルが魅力的である
Perplexityは引用元を「ソース」としてカード形式で表示します。このカードにはページのタイトルと画像が表示されるため、タイトルの質がカードのクリック率を左右します。検索結果と同様、Perplexityのソースカードでも「クリックしたい」と思わせるタイトルを設定することが重要です。
タイトルの最適化については「WordPressの記事タイトルをAIで最適化する方法」も合わせてご覧ください。
FAQ形式のコンテンツを持っている
Q&A形式のコンテンツは、PerplexityがユーザーのQに対するAを抽出しやすい構造です。記事内にFAQセクションを設けることで、引用される可能性が上がります。
情報の信頼性が担保されている
著者情報・参照元リンク・運営者情報が整備されているページは、Perplexityの信頼性評価が上がります。根拠のない情報や出典不明の数値を多用しているページは引用されにくくなります。
llms.txtが設置されている
llms.txtはPerplexityBotがサイトを効率的に理解するための道標になります。サイトの概要・主要コンテンツの一覧・更新情報が整理されたllms.txtが存在すると、クローラーがサイト全体の構造を把握しやすくなります。
4. Perplexity対策の3ステップ
WordPressサイトでPerplexityへの引用を狙うための対策を、優先度の高い順に整理します。
ステップ1:PerplexityBotのクロールを許可する(前提確認)
まず現在のrobots.txtを確認し、PerplexityBotがブロックされていないかチェックします。ブロックされていれば、どれだけコンテンツを改善してもPerplexityには表示されません。
ステップ2:llms.txtを設置する
LLMクローラーに対してサイトの構造・主要コンテンツを伝えるllms.txtを設置します。手動で作成・設置することもできますが、記事数が多いサイトでは自動生成プラグインの活用が現実的です。
ステップ3:コンテンツ構造を「回答しやすい形」に整える
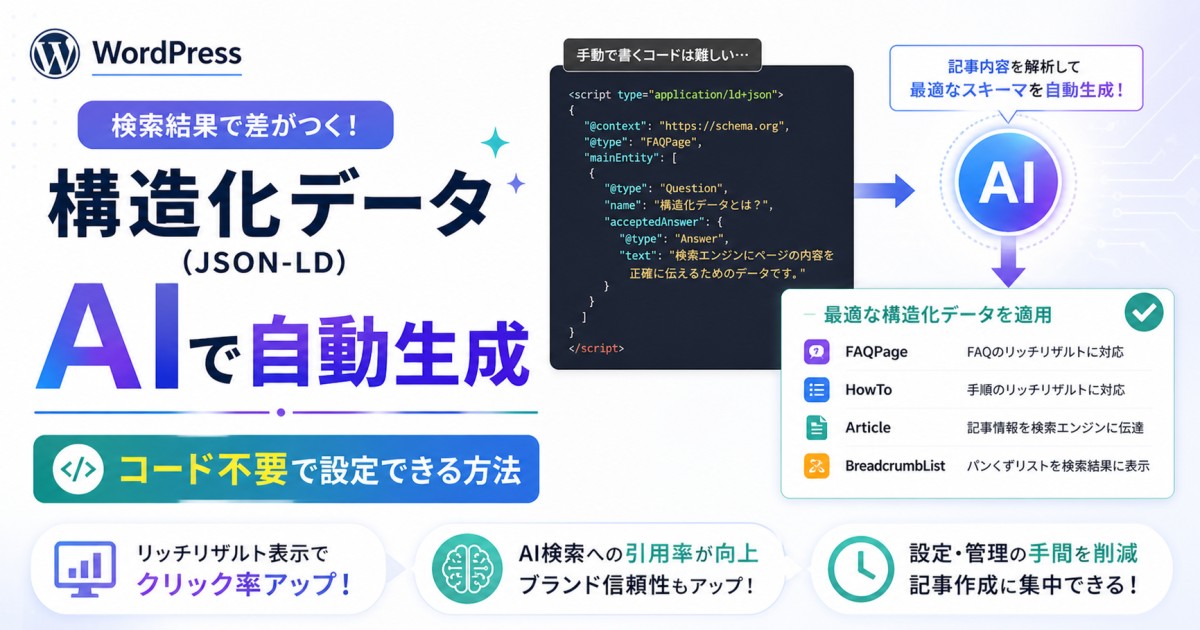
既存記事の書き出しを結論ファーストに修正し、FAQセクションを追加します。構造化データ(FAQPage・Article・HowToスキーマ)の実装も合わせて行うと効果的です。
5. llms.txtの設置方法(WordPressでの具体的な手順)
llms.txtとは
llms.txtはllmstxt.orgが提唱し、Perplexity・ChatGPT・Claudeなど主要AIが参照し始めている業界のベストプラクティスです。robots.txtと似た役割を持ちますが、AIクローラー向けにサイトの内容をMarkdown形式でまとめたファイルです。
手動で設置する場合
以下の形式でllms.txtを作成し、WordPressのルートディレクトリ(public_html/直下)にFTPでアップロードします。
# サイト名
> サイトの概要・ターゲット読者・提供している情報を2〜3文で記述します。
## 主要コンテンツ
- [記事タイトル1](https://example.com/article1/): 記事の概要を1行で
- [記事タイトル2](https://example.com/article2/): 記事の概要を1行で
## 運営者情報
- 運営者:〇〇
- 問い合わせ:https://example.com/contact/手動設置のデメリット: 記事を追加するたびに手動で更新が必要です。更新を怠ると古い情報のままになり、新しい記事がPerplexityBotに認識されにくくなります。
R-LLM SEOで自動生成する場合(推奨)
R-LLM SEOのF08機能を使うと、WordPressの投稿一覧をAIが分析してllms.txtを自動生成・動的配信します。
- 「R-LLM SEO → llms.txt設定」を開く
- サイトの概要・ターゲット読者を入力
- 「llms.txt生成」を実行
- 生成されたファイルを確認・編集
- 「配信を有効にする」をオンにする
設定後はhttps://yoursite.com/llms.txtにアクセスして内容を確認してください。新しい記事を公開するたびに自動で更新されるため、常に最新のコンテンツ一覧がPerplexityBotに伝わります。
仮想配信の仕組みについて: R-LLM SEOのllms.txtはサーバー上に物理ファイルとして書き出されるのではなく、WordPressのフック経由で動的に生成・配信される仕組みです。そのためFTPでサーバーを確認してもllms.txtファイルは見当たりませんが、https://yoursite.com/llms.txtへのアクセスには正常に応答します。サーバーへの書き込み権限が不要な点も、この仮想配信方式のメリットです。
注意:キャッシュ・CDNの除外設定 WP RocketなどのキャッシュプラグインやCloudflare等のCDNを使用している場合、
/llms.txtが古い情報のままキャッシュされる可能性があります。動的配信の効果を損なわないよう、/llms.txtをキャッシュ除外リストに追加してください。LiteSpeed Cacheを使用している場合も同様に除外設定を確認してください。
6. 引用されやすいコンテンツの書き方
llms.txtの設置と並行して、コンテンツ自体をPerplexityに引用されやすい形に整えます。
書き出しで結論を述べる
引用されにくい書き方: 「近年、AI検索の普及が進んでいます。その中でPerplexityというサービスが注目されています。今回はPerplexityに引用されるための方法を解説します。」
引用されやすい書き方: 「Perplexityに引用されるには、①PerplexityBotのクロール許可確認、②llms.txtの設置、③結論ファーストのコンテンツ構造の整備、の3ステップが基本です。」
冒頭の2〜3文でユーザーの質問に答える形を取ると、Perplexityが回答文の引用元として選びやすくなります。
FAQセクションを設ける
記事の末尾または本文中に、読者が抱えやすい疑問をQ&A形式で記述します。FAQPageスキーマを合わせて実装すると、構造化データとしても評価されます。
数値・根拠を明示する
「効果があります」よりも「CTRが平均2.3倍改善した(出典:〇〇調査)」のように、数値と出典を明示した記述はPerplexityの信頼性評価が上がります。一次情報・公的機関・査読済み論文へのリンクは特に有効です。
更新日を明示し、情報の鮮度を保つ
Perplexityの最大の特徴のひとつは、Googleよりも「今のWebの状態」をリアルタイムに反映しようとする点にあります。更新日が古いページや、情報の鮮度が保たれていないページは引用されにくくなります。
定期的に内容を確認・更新し、WordPressの更新日フィールドを適切に管理することが基本です。加えて、R-LLM SEOのF08(llms.txt動的配信)を使えば、記事を公開・更新した瞬間にllms.txtが自動で最新状態に切り替わります。手動でllms.txtを管理している場合、更新作業が漏れると新しい記事が数週間〜数ヶ月単位でクローラーに認識されないリスクがあります。動的配信はこのタイムラグをゼロにする、Perplexity対策における実質的な差別化ポイントです。
7. 引用状況の確認方法
PerplexityBotのクロールを確認する
サーバーのアクセスログでPerplexityBotを検索します。クロールされていれば該当のログが確認できます。
Perplexityで実際に検索して確認する
自サイトが扱うテーマのキーワードでPerplexityを検索し、引用元に自サイトが表示されているかを目視で確認します。特定のキーワードで競合が引用されているのに自サイトが表示されない場合、そのキーワードに関連する記事の構造改善を優先します。
llms.txtへのアクセスを確認する
サーバーのアクセスログで/llms.txtへのアクセスを確認します。PerplexityBotが/llms.txtを取得しているログがあれば、クローラーがサイトの構造を把握し始めているサインです。
コラム:Perplexity自身に「この記事を評価してもらう」 記事を公開したら、Perplexityに「この記事はPerplexityに引用されやすい構造になっていますか?」と質問してみるのも有効です。記事のURLを貼り付けて、構造・信頼性・FAQ整備などの観点からフィードバックをもらうことができます。Perplexity自身から「引用に値する」という評価を得られれば、それをSNSでシェアするマーケティング上の価値もあります。
8. まとめ
Perplexityへの引用対策は、以下の3ステップが基本です。
- PerplexityBotのクロールを許可する(robots.txtを確認)
- llms.txtを設置・自動更新する(新記事が即座に反映される環境を作る)
- コンテンツを結論ファースト・FAQ構造に整える
Perplexity対策に特化した競合記事はまだ少なく、今から対応することで先行者利益が得やすい領域です。llms.txtの設置はサーバーへの書き込みが不要な仮想配信方式のプラグインを使えば数分で完了します。
まずは7日間の無料トライアル(クレジットカード不要)で、llms.txtの自動生成と動的配信を試してみてください。
👉 R-LLM SEOを無料で試す → r-llm.com
👉 WordPress.orgからインストール → R-LLM SEO プラグイン
このシリーズの他の記事
- WordPressのLLMO対策とは?AI検索時代のSEOをわかりやすく解説【2026年版】
- WordPressのメタディスクリプションをAIで自動生成する方法|CTRを改善する書き方とプラグイン比較
- WordPressの記事タイトルをAIで最適化する方法|クリック率が上がるSEOタイトルの作り方
- Google AI Overviewに引用されるための対策|WordPressで今すぐできる施策まとめ
- WordPressの記事をAIでリライトする方法|品質を上げる4つのモードと優先順位の決め方
よくある質問(FAQ)
Q. llms.txtを設置するとGoogleの検索順位に影響しますか?
A. 直接的な影響はありません。llms.txtはAIクローラー向けのファイルであり、GooglebotはGoogleのrobots.txt仕様に従ってクロールするため、llms.txtの有無で検索順位が変わることはありません。
Q. PerplexityBotをrobots.txtでブロックしたほうが良い場合はありますか?
A. コンテンツの無断利用を懸念する場合など、意図的にブロックする選択肢もあります。ただしブロックするとPerplexityへの引用は一切されなくなります。引用によるブランド露出・トラフィック獲得を重視するなら許可する設定を推奨します。
Q. llms.txtを設置してからPerplexityに引用されるまでどのくらいかかりますか?
A. PerplexityBotのクロール頻度やサイトの評価によって異なります。設置直後から数日以内にクロールされるケースもあれば、数週間かかる場合もあります。llms.txtへのアクセスログを定期的に確認することで、クロール状況を把握できます。
Q. FTPでサーバーを確認してもllms.txtファイルが見当たらないのですが、正常ですか?
A. R-LLM SEOを使って設置した場合は正常です。R-LLM SEOのllms.txtはWordPressのフックを通じて動的に生成・配信される仮想配信方式のため、サーバー上に物理ファイルは存在しません。ブラウザでhttps://yoursite.com/llms.txtにアクセスして内容が表示されれば、正常に配信されています。
Q. Perplexity以外のAI検索にも同じ対策が有効ですか?
A. はい。llms.txtはChatGPT・Claude・Geminiなど他の主要AIクローラーも参照するベストプラクティスです。Perplexity対策として設置したllms.txtは、他のAI検索エンジンへの対応としても同時に機能します。
この記事の情報は執筆時点のものです。Perplexityの仕様・クローラーの動作は変化することがあります。
ご質問はお問い合わせページからお気軽にどうぞ。